DeepSeek Engram Architecture: A New Axis of Sparsity for LLMs
- Aisha Washington

- Jan 13
- 6 min read

The current trajectory of Large Language Models (LLMs) often feels like a brute-force contest: add more layers, consume more VRAM, and hope the model remembers everything. DeepSeek has taken a different approach with the release of the DeepSeek Engram. Instead of forcing a neural network to memorize every static fact within its expensive weights, Engram introduces a dedicated mechanism for "Conditional Memory."
This isn't just a minor optimization. It represents a fundamental shift in how we might build the next generation of models, including the anticipated DeepSeek-V4. By offloading static knowledge to a scalable, O(1) lookup table, developers can potentially reduce training costs while improving how models handle factual data.
Why DeepSeek Engram Matters: The Engineer’s Perspective

Before looking at the raw architecture, we need to understand the user experience and the technical bottlenecks DeepSeek Engram addresses.
Deep Learning researchers and power users have long complained about the inefficiency of Transformers. Why should a model spend expensive GPU cycles computing the relationship between "Paris" and "France" every single time? That is static knowledge.
The community reaction to Engram highlights a clear consensus: we need to separate "thinking" from "knowing."
The "Brain vs. Reference Book" Paradigm
Discussions among early adopters and architecture analysts suggest that Engram functions like a reference book for the neural network. The core model (the Backbone) acts as the brain, handling logic, reasoning, and grammar. The DeepSeek Engram module acts as the encyclopedia.
When the model encounters a common pattern or a static fact, it shouldn't need to "think" about it. It should just look it up. This architectural split allows the heavy lifting of the neural network (MoE or Dense layers) to focus on complex reasoning rather than simple fact regurgitation.
Technical Speculation: The Fusion Mechanism
Technical users analyzing the paper and code have reverse-engineered the likely interaction between the memory and the model states. The fusion seems to follow a logic where the new hidden state is a combination of the old state and a gated memory vector.
The prevailing theory is a formula resembling:h_new = h_old + gate (W memory_vector)
This implies that the model learns when to trust its internal reasoning and when to pull from the DeepSeek Engram lookup table. It’s a dynamic, learned behavior, not a hard-coded rule.
Unpacking the DeepSeek Engram Technology
At its heart, DeepSeek Engram is a modernized application of N-gram embeddings. N-grams were the standard for language modeling years ago, simply counting the probability of word sequences. DeepSeek has resurrected this concept, modernized it with vector embeddings, and integrated it directly into the Transformer backbone.
The Power of O(1) Lookup
The most significant claim in the documentation is the achievement of O(1) complexity. In computer science terms, this means the time it takes to retrieve information doesn't grow as the amount of data grows.
Whether your lookup table has 1 million entries or 100 billion entries, the DeepSeek Engram retrieves the relevant vector in the same amount of time. This is achieved through hash mapping. By hashing the input sequence, the system instantly locates the pre-computed embedding without scanning the entire dataset.
Is This Just RAG?
A common point of confusion is comparing this to Retrieval Augmented Generation (RAG). They are not the same.
RAG: An external process where a search engine finds text and feeds it into the model's context window. It's slow and distinct from the model's weights.
DeepSeek Engram: An internal architectural component. The lookup happens inside the model's forward pass. The retrieved vectors are mathematically fused with the model's hidden states. It is a primitive for knowledge lookup native to the model itself.
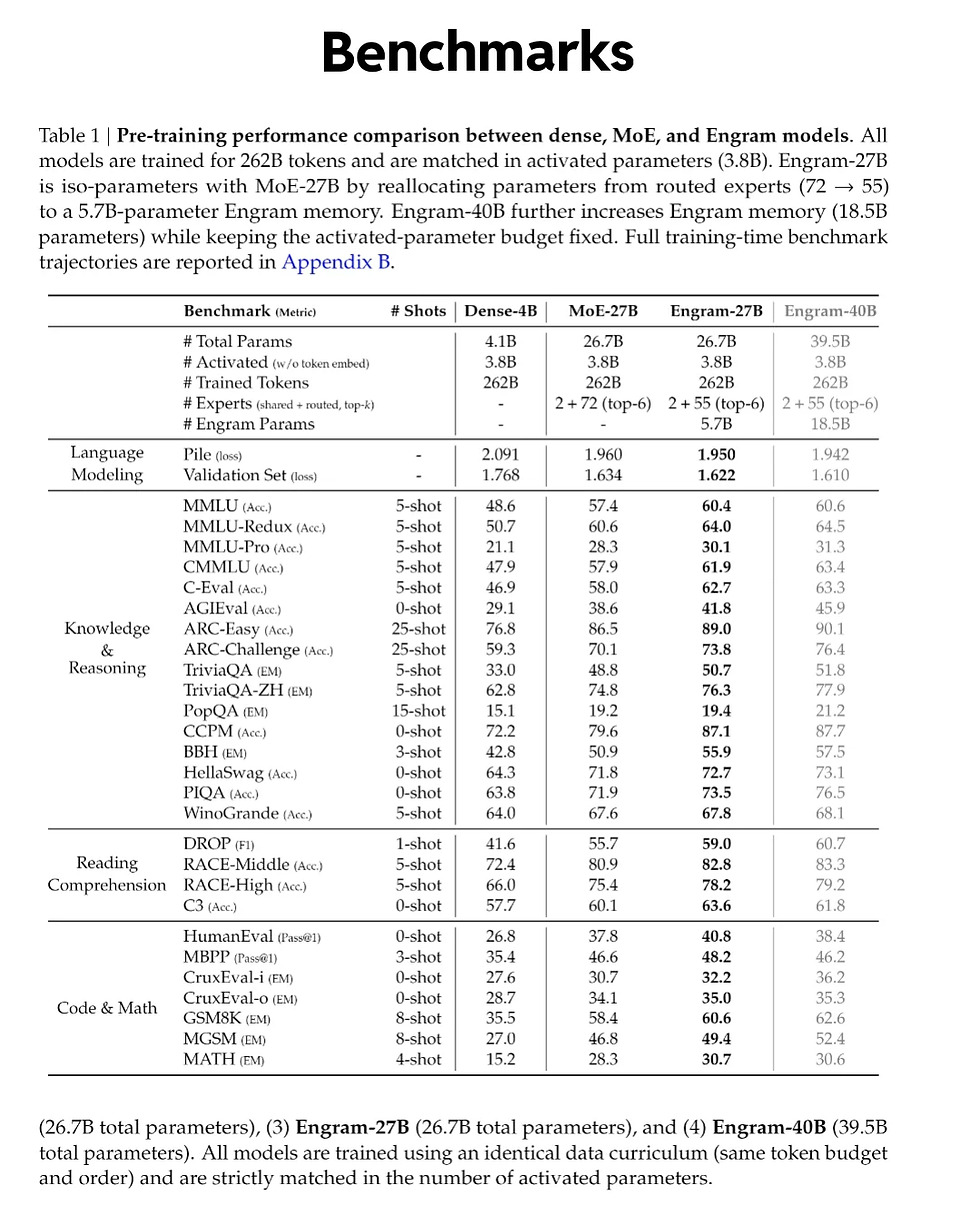
Performance Data: The U-Shaped Scaling Law

DeepSeek didn't just release code; they validated the theory with data. The performance metrics reveal a "U-shaped Scaling Law" that governs the relationship between neural computation and memory capacity.
Finding the Sweet Spot
There is an optimal balance between the size of the traditional Neural Network (like Mixture of Experts) and the size of the DeepSeek Engram memory table.
Too much Memory: If you rely entirely on lookup tables, the model loses the ability to reason and generalize.
Too much Compute: If you rely entirely on the neural network, you waste parameter space memorizing static text, making the model inefficient.
The sweet spot lies in the middle. In testing, an Engram-27B model (optimized with this balance) outperformed baseline Mixture of Experts (MoE) models on standard benchmarks, specifically in knowledge retention, code generation, and mathematical reasoning. This was achieved under "iso-parameter" constraints, meaning both models had roughly the same resource footprint, but the Engram architecture used those resources better.
Host Memory Offloading
One of the most practical features for deployment is the ability to offload the massive embedding tables to Host Memory (RAM). Since the lookup is sparse and efficient, the GPU doesn't need to hold the entire database. This drastically lowers the VRAM requirements for running high-knowledge models, making local deployment of "smart" models more feasible on consumer hardware.
Future Implications: What Users Actually Want
The release of DeepSeek Engram has triggered a wave of feature requests and theoretical applications from the AI community. The following trends represent high-value areas for future development.
The Demand for Pluggable Engrams
The most vocal request from developers is the ability to update the Engram table without retraining the backbone model.
Currently, if an LLM doesn't know a new coding library released yesterday, you have to retrain it. This takes weeks and costs massive amounts of compute. Users envision a future where the DeepSeek Engram layer is "pluggable." You could download a weekly "knowledge patch"—a purely static update to the lookup table—that teaches the model new facts immediately. This would revolutionize how we handle model cut-off dates.
Integration with State Space Models (Mamba)
Another fascinating avenue is combining Engram with State Space Models (SSMs) like Mamba. Advanced users suggest upgrading the N-gram lookup to a "State Cache."
Instead of just retrieving a word embedding, the system could retrieve a pre-computed SSM state. This would function like a "save game" file for the model. If the model encounters a long context it has seen before, it could instantly load the "state" from the lookup table, effectively giving it infinite memory for that specific context without re-processing the tokens.
The "Historian" Expert
There is also a proposal for a specialized "Historian" expert within the MoE architecture. In this setup, standard experts would handle short-term syntax and immediate logic, while a dedicated DeepSeek Engram expert would handle long-term semantic hashing. This specialization would further refine the efficiency of the network.
Getting Started with DeepSeek Engram

For engineers looking to test this architecture, DeepSeek has provided a clear entry point via their GitHub repository.
Requirements
The implementation is relatively lightweight regarding dependencies. You need a standard Python environment (3.8+) with PyTorch.
codeBash
pip install torch numpy transformers sympyRunning the Demo
The repository includes a standalone script, engram_demo_v1.py. It is crucial to note that this script mocks several heavy components (like the actual Attention mechanism and MoE routing) to isolate and demonstrate the DeepSeek Engram logic. It is a learning tool, not a production inference engine yet.
Running this script allows you to trace the data flow: how text is tokenized, hashed, mapped to the memory table, and how those vectors are retrieved.
FAQ: Common Questions on DeepSeek Engram
Is DeepSeek Engram compatible with existing Transformer models?
It requires architectural changes. You cannot simply drop it into Llama 3 or GPT-4. It serves as a foundational component for new architectures, likely serving as the backbone for DeepSeek-V4.
Does this replace Vector Databases (Pinecone, Milvus)?
No. Vector databases are for external document retrieval (RAG). DeepSeek Engram is for internal model parameter efficiency. However, it reduces the hallucination rate, potentially lowering the heavy reliance on external vector stores for basic facts.
Can I run this on a single GPU?
Yes, for smaller implementations. Because the heavy embedding tables can be offloaded to system RAM, the GPU only needs to handle the computation layers. This makes it highly efficient for inference on consumer hardware with high system RAM but limited VRAM.
How is this different from sparse attention?
Sparse attention reduces the computational cost of looking at the context window (the prompt). DeepSeek Engram reduces the computational cost of accessing the model's training data (its long-term memory). They solve different problems.
When will we see a full model using this?
While the code is available now, speculation points to a February release window for a major DeepSeek model (potentially V4) that utilizes this architecture at scale.
The Shift Toward "Thinner" Reasoning
The release of DeepSeek Engram signals a maturity in LLM design. We are moving past the phase of simply making models larger. We are now making them structured.
By identifying that "memory" and "reasoning" are distinct mechanical processes, DeepSeek has opened a door to models that are not necessarily bigger, but significantly denser in capability. If the community's theory on "pluggable knowledge" proves viable, we might be looking at the end of the "static model" era and the beginning of modular, updateable AI.


