Microsoft VibeVoice 将简单脚本转化为 90‑分钟多说话者 AI 播客
- Aisha Washington

- 1小时前
- 讀畢需時 13 分鐘
Microsoft VibeVoice and why it matters
Microsoft VibeVoice is an experimental AI system that can generate a full, multi‑speaker podcast from text, including continuous 90‑minute episodes in English and Mandarin, according to Windows Central’s coverage of the demo. The project is presented as an open research and demo effort on the VibeVoice official overview site, and its core promise is straightforward: turn simple scripts or outlines into long‑form, multi‑voice audio using AI.
Why this matters: creators, producers, and enterprises can potentially move from idea to publishable audio far faster, reach broader multilingual audiences, and personalize listening experiences at scale. VibeVoice’s ability to synthesize multi‑speaker long‑form audio — including simulated interviews, panel discussions, or serialized episodes — changes assumptions about how much time, talent, and budget are required to ship podcast content.
What you’ll learn in this article: how VibeVoice works and what it does best, the technical approach behind long‑context multi‑speaker generation, real use cases (from indie creators to enterprise communications), market implications, ethical and legal questions, and concrete tips for integrating VibeVoice into a production workflow.
Keyword placement note: the opening paragraph and subheadings include the core phrasing from the title so content aligns with search intent for Microsoft VibeVoice and 90‑minute multi‑speaker podcasts.
Insight: VibeVoice reframes long‑form audio as a text‑driven creative output rather than an exclusively studio‑centric product.
Key takeaway: VibeVoice promises to democratize long‑form, multi‑voice podcast production by converting text into continuous audio at scale.
What is Microsoft VibeVoice: core features and capabilities

VibeVoice is Microsoft’s open research and demo project for transforming text into multi‑speaker, long‑form audio. Built as an exploration into text‑to‑speech (TTS) and conversational audio, the project demonstrates that models can synthesize extended, coherent episodes with multiple distinct voices and natural dialog flow.
Core features at a glance:
Multi‑speaker dialogue modeling that simulates speaker turns and conversational dynamics.
Continuous generation for episodes up to and exceeding 90 minutes without obvious breakdowns in cohesion.
Multilingual support, initially focused on English and Mandarin, enabling straightforward bilingual editions.
Voice customization and persona controls for tone, pace, and role (host, guest, narrator).
Demo access and open research releases intended for experimentation rather than turnkey commercial deployment.
Analytics India Magazine describes VibeVoice as an open‑source step toward production‑scale TTS models that emphasize long context and multi‑turn speech, calling out the project’s emphasis on research reproducibility and community experimentation.
Multi‑speaker and long‑form audio capabilities
VibeVoice models speaker turns and conversational flow so episodes sound like real conversations with distinct speakers. It preserves prosody and conversational cues across long stretches, rather than producing short, disjointed clips. This means a scripted roundtable or an adapted long interview can play out over 90 minutes with consistent pacing and natural interjections.
Example: an indie producer could feed a prepared script that interleaves host monologues, two guest replies, and a closing summary; VibeVoice will render distinct vocal identities for each role and keep timing natural across the full runtime.
Actionable takeaway: Use structured scripts with explicit speaker labels and stage directions to maximize turn‑taking accuracy when generating long episodes.
Language support and personalization features
The current VibeVoice demos focus on English and Mandarin, offering localized prosody and idiomatic phrasing per language. Personalization features include voice cloning or voice style controls for pitch, cadence, and emotional valence so creators can match a voice to a persona or brand. The system also supports topical conditioning — leaning into a technical, casual, or narrative tone based on the supplied script.
Example: producing a bilingual episode where the host speaks English and a co‑host replies in Mandarin for a global audience.
Actionable takeaway: Test short bilingual segments first to validate code‑switching quality before committing to full-length multilingual episodes.
Access and experimentation options
VibeVoice is presented as both a live demo and an open research release. Creators can try online demos, run local or cloud instances when open models are available, and integrate the models into pipelines for automated generation or editorial workflows.
The official VibeVoice site provides demos and documentation for those who want to experiment with model releases, while community portals and mirror demos often collect sample prompts and usage tips.
Actionable takeaway: Start by running the public demo to understand how the model maps text to multiple speaker outputs, then iterate with small test scripts before scaling.
Insight: VibeVoice blends research openness with practical demos so teams can experiment without immediately committing to a commercial license.
Key takeaway: VibeVoice delivers multi‑speaker, long‑form audio with personalization and multilingual capabilities intended for experimentation and rapid prototyping.
How Microsoft VibeVoice works: technical approach to long‑form multi‑speaker audio

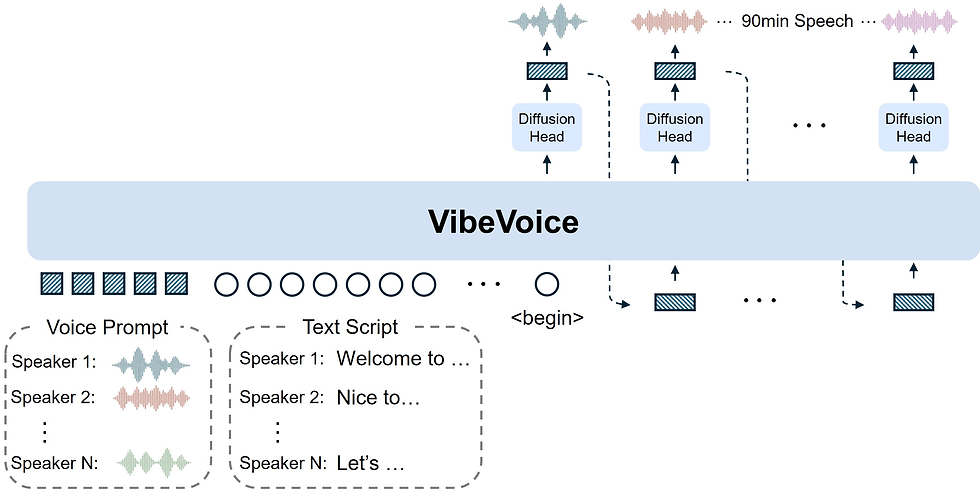
VibeVoice’s research report situates the project within a lineage of TTS and conversational audio models that prioritize long context and speaker continuity. The technical foundations combine large‑scale acoustic models, dialogue conditioning, and strategies to avoid voice drift over extended durations. The authors detail methods for extending coherence across 90 minutes using hierarchical modeling and memory mechanisms in their technical writeup.
The VibeVoice technical report on arXiv outlines model design choices aimed at sustaining coherence in 90‑minute outputs, and related long‑context audio research provides context for memory and decoding strategies used in the project as discussed in related research literature.
Model architecture and training methods
At a high level, VibeVoice employs a backbone that maps textual input and speaker directives into acoustic frames through several stages: 1. Linguistic encoding: converting text into phoneme or phonetic representations conditioned on prosodic markers. 2. Speaker conditioning: speaker embeddings (learned numeric vectors representing voice identity) inform the acoustic generator which vocal traits to produce. 3. Acoustic synthesis: a generative decoder renders audio frames or spectrograms that are finally converted to waveform audio via vocoder components.
Training leverages diverse multi‑speaker datasets, curated long‑form dialog samples, and bilingual corpora to teach both naturalness and turn‑taking patterns.
Example: during training the model sees examples of roundtables, interviews, and scripted plays so it learns when to place short overlaps, fillers, or breath cues.
Actionable takeaway: For custom deployments, fine‑tune on domain‑specific long conversations (e.g., company town halls) to improve domain coherence.
Handling long context and audio coherence
Sustaining coherence across 90 minutes is non‑trivial. VibeVoice uses a mix of architectural and operational techniques:
Hierarchical decoding where high‑level structures (episode segments, scene boundaries) guide lower‑level decoding.
Sliding memory buffers that carry forward recent prosodic context and speaker state to the next chunk.
Overlap‑and‑blend chunking that generates audio in overlapping windows, then aligns and stitches to avoid abrupt transitions.
These approaches reduce prosody drift, maintain narrative arcs, and preserve consistent pacing over long runtime.
Insight: Long‑form audio relies as much on structural context (e.g., scene markers, speaker roles) as on local acoustic generation.
Actionable takeaway: When scripting for VibeVoice, include explicit scene and segment markers in text prompts to help the model create consistent long‑form structure.
Multi‑speaker modeling and voice consistency
Speaker embeddings act as persistent IDs across an episode. VibeVoice also applies constraints during decoding to prevent voice drift — the gradual change in timbre or prosodic traits that can make a single speaker sound inconsistent. Techniques include periodic reconditioning on a short reference audio, enforcing pitch and spectral priors, and limiting low‑level sampling entropy for identity‑sensitive layers.
The model also balances scripted turns with natural‑sounding disfluencies — short “uhs” and “hmms” — to mimic human dialog while avoiding excessive artifacts.
Example: generating a 90‑minute panel where each panelist maintains a distinctive timbre and speech pattern throughout, with controlled, believable overlaps during interruptions.
Actionable takeaway: Use reference clips for each desired voice during generation setup to anchor identity and reduce drift in extended outputs.
Research findings and reproducibility
The published technical report presents evaluation metrics for naturalness, speaker similarity, and conversational coherence. Results show that VibeVoice maintains perceptual naturalness and speaker identity across long durations more effectively than baseline short‑context TTS models. The authors also provide reproducibility notes and checkpoints for community experiments.
Actionable takeaway: Reproducibility materials and checkpoints make it possible for studios and labs to benchmark VibeVoice‑style outputs against commercial TTS services.
Insight: Scaling TTS from seconds to hours shifts the evaluation focus from pure audio quality to long‑term identity and narrative structure.
Key takeaway: VibeVoice’s architecture and training emphasize hierarchical context, memory strategies, and speaker conditioning to achieve coherent multi‑speaker audio over 90 minutes.
Use cases and integrations: Microsoft Copilot podcasts and adapting content into audio

VibeVoice’s long‑form capabilities unlock a variety of practical applications, from serialized creative podcasts to automated enterprise briefings and academic content conversions. The system can be integrated into content pipelines where text is the primary asset and audio is a render target.
Windows Central covered Microsoft’s announcement of Copilot podcasts, describing how Copilot will generate personalized audio experiences that mirror VibeVoice‑style capabilities. In research contexts, projects like PaperWave transform academic papers into conversational audio formats, showcasing how long‑form TTS can improve accessibility and engagement.
Insight: Text becomes the single source of truth for multi‑modal distribution when long‑form multi‑speaker audio is as easy to generate as a draft.
Creator and indie podcaster scenarios
Indie creators can dramatically shorten production cycles:
Draft an episode in a few hours, label roles, and generate a multi‑speaker audio file for review.
Produce multilingual editions quickly by generating parallel English and Mandarin versions.
Experiment with multiple voice personas without casting or studio sessions.
Example: an independent narrative podcast could prototype alternative host dynamics (e.g., two co‑hosts vs. a host/interviewer format) by swapping speaker labels and regenerating audio within the same day.
Actionable takeaway: Start with short pilot episodes to refine voice choices and pacing before committing to season production.
Enterprise and internal communications
Enterprises can automate employee communications and training:
Generate multilingual town halls or executive briefings for global teams.
Create on‑demand compliance modules with simulated interviewer interactions to make content feel conversational.
Personalize audio briefings dynamically based on role or region.
Example: an HR team could produce weekly personalized audio summaries of policy changes tailored to different departments using the same source text.
Actionable takeaway: Use VibeVoice for prototypes, then establish a QA loop with human review for compliance and brand voice checks.
Research and academic content conversion
Converting papers or lectures to conversational audio increases accessibility and retention. Projects like , turning dense text into an interview or panel that highlights key findings and implications for non‑specialist listeners.
Actionable takeaway: Work with domain experts to create accurate, narrative‑friendly scripts that preserve nuance before automated generation.
Microsoft Copilot podcasts integration
Copilot podcasts envision a personalized audio feed where an AI host curates topics and generates episodes on demand. Such integrations pair language models (for summarization and script generation) with VibeVoice‑style audio synthesis for rendering multi‑speaker conversations tailored to user preferences.
Example: a user requests a “25‑minute briefing on climate policy,” and Copilot produces a short episode with a virtual host and two expert voices drawn from summarized source material.
Actionable takeaway: When using Copilot‑driven audio, add editorial oversight and citation tracks to maintain factual accuracy.
Key takeaway: VibeVoice’s ability to turn written materials into long‑form conversational audio enables new content formats — serialized fiction, dynamic briefings, and educated audio summaries — across creators and organizations.
Industry impact and market trends for AI in podcasting with VibeVoice context

AI in podcasting is rapidly moving from experimental tools to production aids that reshape workflows and monetization models. Market reports indicate growth in AI‑powered audio tools and increasing investment in personalized audio technologies. VibeVoice sits at the intersection of research openness and practical audio production, influencing both commercial vendors and startup innovation.
The Business Research Company’s market analysis highlights a growing global market for AI in podcasting, driven by efficiency gains and new ad models. Commentary and practitioner analysis emphasize how AI is changing production economics and distribution strategies as covered by industry analysis of AI’s effects on podcasting workflows.
Insight: Time‑to‑publish and per‑episode marginal cost are primary levers for AI’s disruption of podcast production economics.
Market size and growth projections
Key market drivers include automated production tools, dynamic ad insertion, and personalization services. AI‑powered audio generation reduces fixed costs (studio time, talent booking) and enables variable pricing models where personalized episodes justify premium subscription tiers.
Actionable takeaway: Podcasters and networks should model potential cost savings from automation against the need for post‑production human QC and legal compliance.
Disruption to production and distribution
Automation shortens production cycles, enabling:
Faster topical episodes and news recaps.
Increased episode volume for networks aiming to boost engagement metrics.
New roles: prompt engineer, AI audio editor, and ethics reviewer instead of traditional host booking logistics.
Example: a news network could prototype same‑day audio explainers synthesized from journalist summaries rather than scheduling recording sessions.
Actionable takeaway: Reassess staffing and skill requirements to include AI‑oriented roles like prompt design and audio quality auditing.
Listener experience and monetization opportunities
Personalized audio feeds and real‑time ad tailoring open new monetization channels. AI can insert dynamic ads informed by listener profile or region, and create personalized show intros or summaries that improve retention.
Actionable takeaway: Test dynamic ad formats on small cohorts before full rollout to evaluate acceptability and CPM impacts.
Competitive and ecosystem considerations
VibeVoice’s open research orientation positions it as both a template for startups and a benchmark for commercial vendors. The model sits alongside paid TTS providers and emerging startups; its open outputs accelerate ecosystem experimentation but also raise questions about productization and service guarantees.
Actionable takeaway: Evaluate VibeVoice‑generated audio against commercial services for latency, licensing, and support — particularly when monetization depends on consistency.
Key takeaway: AI models like VibeVoice are catalysts that shift podcast economics toward rapid, personalized audio but require strategic choices around quality, legal exposure, and listener trust.
Practical integration, tutorials and workflow tips for using VibeVoice in production
Moving from experiment to production requires a practical roadmap. The community has already published hands‑on guides and example prompts to help creators integrate VibeVoice‑style models into existing workflows.
Practical tips and comparisons have appeared in community write‑ups that position VibeVoice capabilities against subscription TTS services, and community‑hosted demos and repositories collect example scripts and usage patterns on sites like vibevoice.online.
Insight: Treat VibeVoice as a fast prototyping engine; production readiness requires layered human review and tooling.
Getting started step by step
Prepare a script with explicit speaker labels and scene markers.
Select or record short reference clips for each voice to improve identity anchoring.
Run short test generations (5–10 minutes) to validate turn taking and prosody.
Generate a full episode, using chunked generation with overlap to maintain coherence.
Conduct a human QA pass focusing on factual accuracy, pacing, and brand voice.
Example prompt: “Host: — warm, inquisitive. Guest A: — measured, analytical. Scene 1: Intro (3 minutes) — host welcomes listeners and sets topics.”
Actionable takeaway: Use iterative mini‑generations to tune persona settings before generating long episodes.
Post production and editing best practices
Post‑production tools remain essential for polishing AI‑generated audio:
Use spectral editors (e.g., iZotope RX) to remove artifacts and smooth transitions.
Align music beds and fades using DAW automation to preserve natural breaths.
Run filler detection to eliminate excessive “ums” or mechanical disfluencies without erasing human‑like authenticity.
Actionable takeaway: Keep a versioned workflow so you can revert to earlier audio if a later processing pass introduces artifacts.
Cost, tooling and alternative services
Open demos and model downloads reduce upfront licensing cost but come with infrastructure and support tradeoffs. Commercial TTS services may offer lower latency, guaranteed SLAs, and turnkey SDKs — useful for high‑volume or revenue‑critical production. Compare per‑minute generation costs, required compute, and support levels before choosing a path.
Actionable takeaway: Prototype on open demos to validate creative fit, then evaluate total cost of ownership before scaling.
Community resources and further learning
Community sites and demo repositories like collect sample prompts, shared persona profiles, and example workflows that expedite learning. Participate in forums, contribute test scripts, and share QA checklists to accelerate dependable production practices.
Actionable takeaway: 尽早加入社区频道——这是发现提示模式和缓解 artifact 的最快方式。
关键要点: VibeVoice 可通过清晰的脚本、迭代测试、稳健的后期制作以及对成本与质量权衡的关注,集成到标准播客流程中。
关于 Microsoft VibeVoice、AI 播客和最佳实践的常见问题

以下是创作者和团队在评估长形式多说话人 AI 音频时常问问题的简洁回答。
What can VibeVoice generate and how long can an episode be? VibeVoice generates multi‑speaker long‑form audio from text and has demos capable of continuous outputs around 90 minutes; experimental runs and demos demonstrate coherent episodes at that scale.
Does VibeVoice support multiple languages and how natural do voices sound? The project emphasizes English and Mandarin, with naturalness rated highly in initial research; however, quality varies by language and depends on available training data and persona tuning.
How do I maintain authenticity and avoid synthetic sounding content? Use script cues for small natural disfluencies, provide short voice reference clips, and perform human editing to adjust pacing and remove unnatural artifacts.
Are there legal or copyright issues when cloning voices or using AI‑generated hosts? Yes — cloning a living person’s voice can raise rights and consent issues. Follow local laws, obtain permissions for cloned voices, and adhere to platform rules and disclosure guidelines.
How does VibeVoice compare to paid TTS services for podcasters? Open demos and research releases often lower cost barriers and allow experimentation, while paid services may offer better SLA, support, and polished SDKs for production use. Evaluate both for quality, cost, and reliability.
What are best practices for editing long AI‑generated audio? Chunk generation with overlap, run spectral cleanup, align music beds, and perform human QA for factual accuracy and pacing.
How should creators disclose AI usage to listeners? Use clear disclosures in show notes and intros, and consider a brief statement at the end of episodes explaining which elements used AI — transparency builds trust.
When is human hosting still preferable to AI generated audio? Human hosts remain preferable for authenticity, live interaction, investigative reporting, sensitive interviews, and when a unique personal brand is central to the show.
可执行要点: 将常见问题用作试点项目的检查清单:测试质量、确认法律许可、披露 AI 使用,并规划人工监督。
结论:趋势与机遇(12–24 个月)及后续步骤
VibeVoice 凸显了 AI 在音频领域的近期轨迹:更长的剧集、多说话人真实感,以及与能自动生成脚本的语言模型更紧密的集成。在未来 12–24 个月内,预计将出现快速迭代、更广泛的语言覆盖以及越来越多的人机混合制作模式。
近期值得关注的趋势:
随着记忆架构的改进,更可靠的长上下文合成。
超越英语和普通话的更广泛多语言支持。
结合摘要、脚本生成和多说话人音频渲染的集成流程(例如 Copilot podcasts)。
动态生成带来的新型广告和个性化模式。
用于 QA、伦理审查和语音权利管理的工具增长。
机遇与第一步: 1. 试播一部短系列:生成三集试播以测试语音角色和剪辑需求。 2. 建立编辑 QA 和法律工作流:创建准确性、许可和披露检查清单。 3. 尝试个性化:为小众受众群体测试简短的个性化开场白或定向广告位。 4. 构建混合形式:将人类主持片段与 AI 生成的专家摘要混合,以降低成本同时保留真实性。 5. 跟踪法规和行业标准:关注语音克隆和披露实践的指导,以保持合规。
权衡与不确定性:质量将持续提升,但关于作者身份、同意和变现的问题仍在演变。开放研究模型加速创新,但要求制作团队承担事实核查和听众信任的责任。
最终可执行步骤: 尝试 VibeVoice 演示以评估创意契合度,在人工监督下运行受控试点剧集,并在广泛发布前采用清晰的披露和 QA 政策。
洞见:VibeVoice 及类似系统并非人类创造力的替代品,而是重新配置音频制作、个性化与规模化方式的强大工具。
关键要点: Microsoft VibeVoice 证明文本可作为 90 分钟多说话人播客的主要创意输入——为创作者和组织提供了以规模化方式制作、个性化与分发音频的新途径,同时要求仔细关注质量、伦理和听众信任。