Agentic Vision Gemini 3 Flash: Moving Beyond Static Image Recognition
- Aisha Washington

- Jan 30
- 5 min read

The release of Agentic Vision Gemini 3 Flash in January 2026 marks a specific shift in how multimodal models handle visual data. We aren't just looking at higher parameter counts or vaguer promises of "better understanding." We are looking at a fundamental change in mechanics: the model now writes and executes Python code to "investigate" an image rather than just staring at it and guessing.
This capabilities update, currently live in Google AI Studio and Vertex AI, attempts to solve the persistent hallucination problems that plague Vision Language Models (VLMs) when they face dense diagrams or counting tasks.
Real-World Feedback on Agentic Vision Gemini 3 Flash
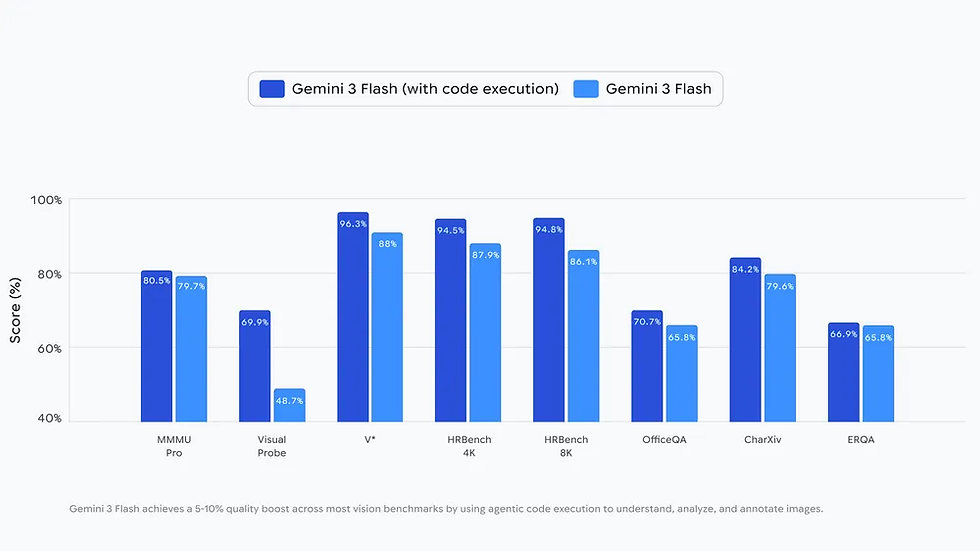
Before diving into the Google architecture diagrams, it is better to look at what happens when developers actually touch the API. The reception on platforms like Reddit and initial developer logs paints a mixed but promising picture of Agentic Vision Gemini 3 Flash.
Success in Complex Data Extraction
Users testing the model on complex charts and technical diagrams report a significant jump in reliability. In previous iterations, asking a model to extract specific data points from a dense scatter plot often resulted in "vibes-based" answers—numbers that looked right but were hallucinated.
Because Agentic Vision Gemini 3 Flash uses code execution, it doesn't just predict the next token; it seemingly runs Python scripts to process the visual information. One user noted that for transcribing complex menus, the speed advantage over OpenAI’s o3 model was substantial, cutting a task that might take 5-10 minutes down to seconds. This suggests the "Flash" architecture is maintaining its low-latency promise even with the overhead of the agentic loop.
The "Mannequin" Failure and Segmentation Limits
It isn't magic, though. A notable stress test involved asking the model to distinguish between real people and mannequins in a photo using bounding boxes. The model failed to annotate them correctly.
This failure highlights a critical distinction: Agentic Vision Gemini 3 Flash is excellent at mathematical and logical "investigation" (counting objects, reading text via OCR scripts, calculating ratios), but it still struggles with semantic segmentation tasks that require deep conceptual understanding of visual context if the code interpretation can't find a programmatic hook. Users are already asking for integrations with specialized segmentation tools like SAM3 to bridge this gap.
Developer Demands
The community feedback loop has been immediate. There is a strong demand to port this feature to the "Pro" series, under the assumption that a larger model brain would write better investigation code. There are also specific complaints about "nerfing," a common sentiment when a model refuses a task it previously might have attempted (even poorly), likely due to stricter safety rails accompanying the new agentic capabilities.
How the Agentic Vision Gemini 3 Flash Loop Works

The core differentiator here is the "Think-Act-Observe" loop. Standard VLMs perform a single pass: they ingest pixels and output text. If the text requires counting 50 tiny objects and the model misses three in the first pass, it can't go back and check.
Agentic Vision Gemini 3 Flash changes the workflow:
Think: The model analyzes the prompt (e.g., "Count the red cars").
Act: It generates Python code to perform an operation, such as cropping the image to zoom in on a specific sector or running a pixel-analysis script.
Observe: It reviews the output of that code.
Iterate: If the data is insufficient, it repeats the process before giving a final answer.
This active investigation allows for "grounding." When the model answers a question about a microchip's serial number, it isn't guessing based on a blurry overview; it has likely "cropped" that section of the image in memory to read it clearly.
Impact on Agentic Vision Gemini 3 Flash Benchmarks
Google claims this iterative approach yields a 5-10% quality improvement across standard vision benchmarks. While benchmark numbers often feel abstract, in this case, the metric correlates directly to the method: the improvement comes from the model's ability to self-correct using tools.
Technical Implementation and Cost
For teams building on Vertex AI or Google AI Studio, the barrier to entry is low, but the cost structure is specific.
Pricing and Efficiency
Agentic Vision Gemini 3 Flash is priced at $0.50 per 1 million input tokens and $3.00 per 1 million output tokens. For audio inputs, the rate doubles to $1.00 per 1M tokens.
Google notes a 30% reduction in token usage compared to Gemini 2.5 Pro. This efficiency gain likely stems from the model solving problems via concise code rather than verbose chain-of-thought text generation. Instead of generating paragraphs of reasoning to convince itself of an answer, it just runs a script.
Using the API
To use Agentic Vision Gemini 3 Flash, developers must enable the Code Execution parameter in the API or the "Tools" section of the AI Studio playground.
There is a granular control available called media_resolution. Developers can toggle this between low, medium, high, and ultra_high.
Low/Medium: Good for general scene description.
High/Ultra_high: Essential for the agentic features to work effectively on fine details like text reading or small object counting.
High resolution increases latency and token consumption, so the best practice is to dynamically adjust this parameter based on the complexity of the user's request.
The Future of Agentic Imaging

The release of Agentic Vision Gemini 3 Flash signals that we are hitting the limits of what "static" neural networks can do with images. The future isn't just bigger models; it's models that use tools.
However, the "Think-Act-Observe" loop introduces new points of failure. If the model writes bad Python code, the visual analysis fails, regardless of how smart the underlying LLM is. The feedback regarding the mannequin test proves that code execution isn't a silver bullet for semantic understanding. It turns vision problems into logic problems, which works for diagrams but less so for nuanced photography.
For now, the utility is undeniable for data processing workflows. We have moved from AI that looks at a spreadsheet screenshot and guesses the total, to AI that writes a script to sum the columns. That is a reliable step forward.
FAQ: Agentic Vision Gemini 3 Flash
Q: Can Agentic Vision Gemini 3 Flash count objects accurately, like skittles in a jar?
A: It performs significantly better than standard models because it can write code to identify and count distinct pixel groups. However, it may still struggle with heavily occluded objects where code-based segmentation fails.
Q: How do I enable the code execution feature for image analysis?
A: In Google AI Studio, go to the "Tools" dropdown menu and toggle "Code Execution" to on. If using the API, you must include the code execution tool definition in your request payload.
Q: Why did users compare Gemini 3 Flash to OpenAI’s o3?
A: Users found Gemini 3 Flash faster for tasks like transcribing menus. While o3 is highly capable, the feedback suggests Gemini’s specific agentic tooling offers a speed advantage in "active" visual tasks.
Q: Does the "Think-Act-Observe" loop increase the cost of using the model?
A: Yes and no. While it might use more processing time per request, Google claims a 30% average saving in token volume because the model solves problems efficiently with code rather than long-winded text reasoning.
Q: Can Agentic Vision Gemini 3 Flash replace segmentation models like SAM?
A: Not yet. User tests show it struggles with semantic boundaries, such as distinguishing between a human and a mannequin. It is best used for logical extraction rather than pixel-perfect segmentation masks.
Q: Is this feature available in the standard Gemini App?
A: Yes, it is rolling out to the Gemini App under the "Thinking" model setting, allowing casual users to access the same agentic capabilities as developers.


