An In-Depth Exploration of Hybrid RAG Architectures and Their Applications
- Olivia Johnson

- Aug 2, 2025
- 12 min read

In today’s rapidly evolving AI landscape, the demand for intelligent systems that can provide accurate, context-aware answers to complex queries has never been higher. RAG-based question answering — or Retrieval-Augmented Generation — has emerged as a powerful paradigm that combines the strengths of information retrieval and generative language models to deliver state-of-the-art performance. This article presents a comprehensive exploration of hybrid RAG architectures, dissecting their design, capabilities, and real-world applications.
Whether you’re an AI researcher, developer, or business leader exploring advanced NLP solutions, this deep dive will equip you with the knowledge to understand, implement, and leverage hybrid RAG models effectively.
Understanding RAG: Foundations of Retrieval-Augmented Generation

Retrieval-Augmented Generation (RAG) is an innovative approach in natural language processing that enriches the generative capabilities of transformer-based language models with external knowledge retrieval components. Unlike purely generative models—like GPT—that rely solely on the information encoded in their parameters, RAG models dynamically query external knowledge bases or document collections to ground their responses in up-to-date, relevant data.
What Makes RAG Unique?
At its core, a RAG model integrates two key mechanisms:
Retriever: Searches a large corpus or database for relevant documents or passages based on the input query.
Generator: Uses retrieved documents as context to generate coherent and factual answers.
This hybrid approach addresses a critical limitation of large language models (LLMs): knowledge cutoff and hallucination. By grounding generation in real documents, RAG models improve factual accuracy and expand their effective knowledge base beyond training data.
How Does RAG Differ from Other QA Approaches?
Traditional question answering systems often fall into two categories:
Extractive QA: Identifies exact answer spans within retrieved documents.
Generative QA: Produces answers in free-form text without explicit grounding.
RAG blends these by retrieving relevant passages but then generatively crafting answers using the retrieved context. This leads to more flexible responses that can synthesize multiple information sources while maintaining factual grounding.
For example, if asked “What are the key benefits of solar energy?”, an extractive QA system might highlight a single sentence from a retrieved article, whereas a generative RAG model can synthesize information from several documents to produce a coherent, comprehensive answer explaining environmental benefits, cost savings, and technological advancements.
The Evolution of Hybrid RAG Architectures
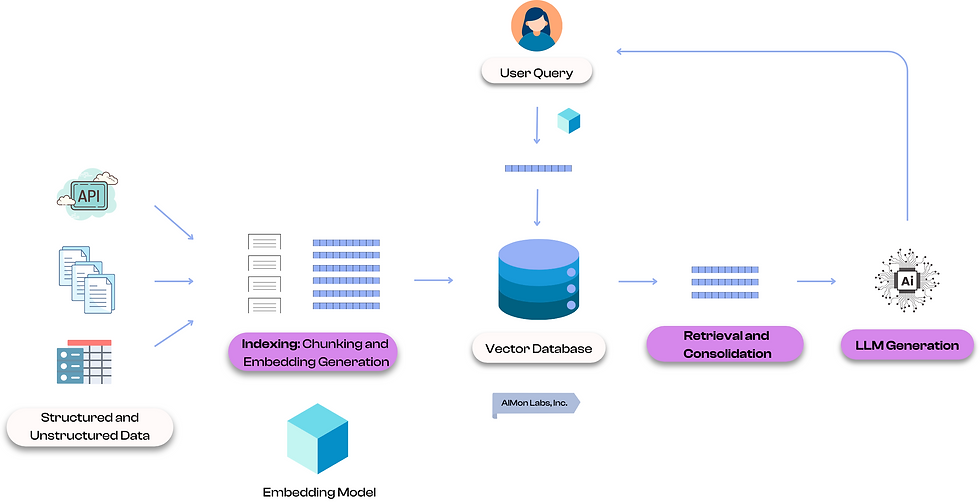
Hybrid RAG architectures represent the next step in retrieval-augmented generation, combining multiple retrieval techniques and model variants to optimize performance across diverse domains.
From Single Retriever to Multi-Retriever Systems
Early RAG implementations typically employed a single retriever—often based on dense vector embeddings—to fetch candidate documents. However, hybrid architectures integrate:
Dense Retrieval: Uses embeddings from transformer encoders to capture semantic similarity. For instance, Dense Passage Retrieval (DPR) encodes queries and documents into a shared vector space, allowing retrieval based on semantic meaning rather than exact keyword matches.
Sparse Retrieval: Based on traditional term-frequency methods like BM25, useful for keyword matching. Sparse retrievers excel in scenarios where exact terms are crucial, such as legal or medical documents with precise terminology.
Cross-encoders: Re-rank retrieved results by modeling query-document interactions at a fine-grained level. Unlike bi-encoders which embed queries and documents separately, cross-encoders jointly encode query and document pairs, enabling more accurate relevance estimation but at higher computational cost.
By combining these retrieval methods, hybrid systems achieve higher precision and recall. For example, a sparse retriever might quickly narrow down candidates based on keywords, a dense retriever expands the search semantically, and a cross-encoder refines ranking to prioritize the most relevant passages.
Fusion-in-Decoder (FiD) and Beyond
One popular hybrid architecture is the Fusion-in-Decoder (FiD) model, which concatenates multiple retrieved passages and feeds them jointly into a sequence-to-sequence generator. This contrasts with early RAG models that generated answers from each passage separately before aggregating outputs.
FiD allows the generator to attend to all retrieved documents simultaneously, enabling complex reasoning and synthesis of information across multiple sources. For example, answering a question about climate change policies may require integrating data from scientific reports, policy documents, and news articles—all of which FiD can process jointly.
Hybrid architectures also explore:
Multi-hop retrieval, where subsequent retrievals depend on previous answers. This enables answering complex questions requiring reasoning across multiple documents. For example, “Who is the CEO of the company that acquired Tesla’s battery supplier?” involves multiple retrieval steps.
Knowledge graph integration, enhancing retrieval with structured data. By linking textual retrieval with graph-based knowledge (entities, relations), models can better understand context and infer implicit connections.
Multi-modal retrieval, incorporating images, tables, or audio alongside text. This is crucial for domains like medicine where diagnostic images or charts complement textual information.
These innovations enable hybrid RAG models to tackle increasingly complex questions that require synthesizing multiple evidence sources.
Core Components of Hybrid RAG Systems
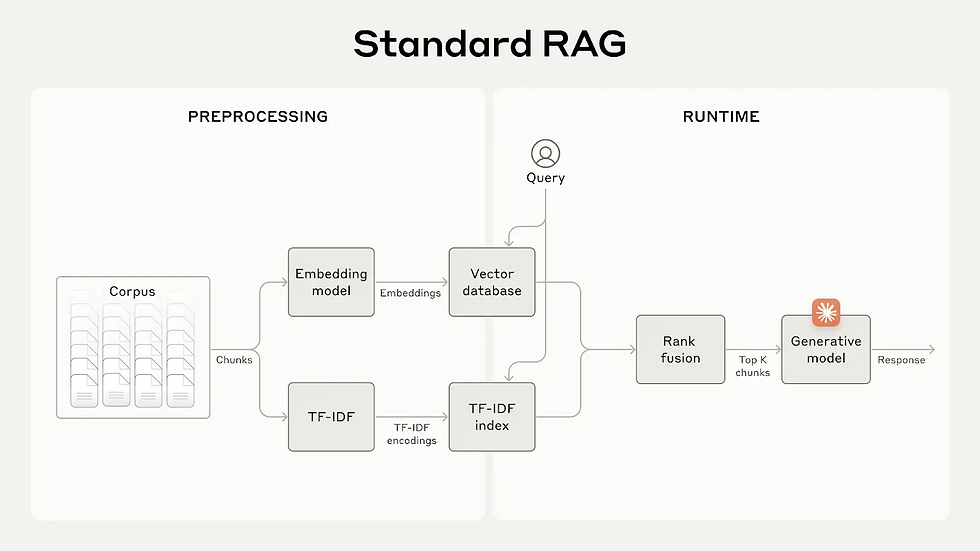
Understanding the building blocks of hybrid RAG architectures is essential for appreciating their power and flexibility.
1. Retriever Module
The retriever acts as the system’s memory access point:
Dense retrievers encode queries and documents into fixed-dimensional embeddings using transformers (e.g., BERT, DPR). These embeddings capture semantic meaning, allowing retrieval of relevant documents even when query and document use different phrasing. For example, a query about “heart attack symptoms” can retrieve documents mentioning “myocardial infarction indicators.”
Sparse retrievers use inverted indices and TF-IDF/BM25 scoring to quickly identify candidate documents based on keyword overlap and term importance. Sparse methods are computationally efficient and effective for exact matches.
Hybrid systems often combine both to balance speed and semantic relevance. For instance, a sparse retriever might provide an initial candidate set rapidly, followed by dense retrieval for semantically relevant but lexically different documents.
Additionally, some systems employ approximate nearest neighbor (ANN) search algorithms (e.g., FAISS, HNSW) to accelerate dense retrieval over millions of documents, enabling real-time applications.
2. Generator Module
The generator is typically a seq2seq transformer such as BART or T5:
It conditions on concatenated retrieved passages, allowing it to attend to multiple contexts simultaneously.
Generates fluent, contextually grounded answers that can combine information from diverse sources.
Can be fine-tuned end-to-end with retrieval components or trained separately. End-to-end fine-tuning aligns retriever and generator objectives, improving overall QA performance.
For example, a T5-based generator trained on biomedical QA datasets can answer complex clinical questions by integrating retrieved research abstracts and guidelines into coherent recommendations.
3. Knowledge Sources
Hybrid RAG systems can tap into various knowledge repositories:
Static corpora (e.g., Wikipedia dumps) provide broad, general knowledge and are easy to index.
Domain-specific databases (legal texts, medical literature) offer specialized, authoritative content critical for high-stakes applications.
Dynamic web indexes or APIs allow access to real-time information such as news, stock data, or social media trends.
Choosing and curating knowledge sources involves trade-offs between freshness, reliability, and coverage. For example, a financial QA system might integrate a live market data API alongside historical reports.
4. Ranking and Re-ranking
Because retrievers can return noisy or irrelevant candidates, hybrid architectures often include re-ranking layers:
Cross-encoders evaluate query-passage pairs with attention mechanisms, providing fine-grained relevance scores.
Learned rankers optimize retrieval precision based on user feedback or labeled data, adapting to domain-specific relevance criteria.
For instance, a customer support chatbot might learn to prioritize FAQs with higher user satisfaction scores through re-ranking.
5. Feedback Loops
Some advanced systems incorporate user interaction signals to refine future retrieval and generation:
Reinforcement learning from human feedback (RLHF) enables models to improve answer quality based on explicit user ratings or corrections.
Active learning dynamically selects uncertain queries for manual annotation, improving retriever accuracy with minimal labeling effort.
By continuously adapting, hybrid RAG systems maintain high performance in evolving environments.
Advantages Over Traditional QA Models

Hybrid RAG architectures transcend limitations inherent in purely generative or extractive QA by offering several distinct advantages:
1. Enhanced Factual Accuracy
By grounding generation on retrieved documents rather than solely internal model parameters, hybrid RAG reduces hallucinations—a common problem with large LLMs—and improves answer verifiability. This is especially vital in domains like healthcare or law where incorrect answers can have serious consequences.
For example, a hybrid RAG model answering medical queries can cite recent clinical studies retrieved at query time, ensuring recommendations reflect the latest evidence.
2. Scalability and Updatability
Since external knowledge bases can be updated independently from the generator model, these systems scale better over time without costly retraining. New documents can be indexed or removed dynamically, allowing the system to stay current with minimal overhead.
This contrasts with pure LLMs, which require expensive retraining or fine-tuning to incorporate new knowledge.
3. Domain Adaptability
Retrieval modules can be customized with domain-specific corpora, allowing hybrid RAG models to excel in specialized fields like healthcare, finance, or legal services. Tailoring retrievers to domain language and terminology improves relevance and precision.
For example, a legal QA system benefits from indexing statutes, case law, and contracts, while a scientific QA system leverages research papers and technical reports.
4. Support for Complex Queries
Multi-hop reasoning enabled by iterative retrieval steps helps answer questions spanning multiple documents or requiring synthesis across data points. This capacity is crucial for tasks like fact-checking, where claims must be verified against several sources.
For example, answering “Which countries signed the Paris Agreement after 2015 and have committed to net-zero emissions by 2050?” requires retrieving and combining data from multiple treaties and climate reports.
According to a study by Microsoft Research (source), hybrid architectures show markedly improved performance on knowledge-intensive tasks compared to baseline LLMs.
Practical Applications of Hybrid RAG in Industry

Hybrid RAG architectures have transformative potential across diverse sectors:
1. Customer Support Automation
Companies deploy hybrid RAG-powered chatbots that retrieve relevant support documents and generate personalized responses, reducing response times and improving user satisfaction. For example, telecom providers use such systems to answer billing queries by pulling from dynamic account data and policy documents.
Hybrid RAG models also enable multi-turn dialogues where follow-up questions depend on context from previous interactions, improving conversational continuity.
2. Medical Information Retrieval
Healthcare providers use hybrid RAG systems to query up-to-date medical literature and clinical guidelines before generating treatment recommendations or patient summaries with high accuracy. For example, oncologists can ask complex questions about drug interactions or trial results, receiving evidence-backed answers citing recent studies.
These systems support clinical decision support tools, reducing diagnostic errors and improving patient outcomes.
3. Legal Research
Law firms leverage hybrid retrieval-generation workflows to sift through vast legal databases and draft case summaries or contract analyses grounded in authentic statutes and precedents. Hybrid RAG enables lawyers to quickly identify relevant cases, extract key arguments, and generate narrative briefs.
This reduces manual research time and improves accuracy in legal drafting.
4. Educational Tools
EdTech platforms integrate hybrid QA to answer student queries by pulling from textbooks, lecture notes, and scholarly articles while adapting explanations for different learning levels. For example, a student asking about “photosynthesis” might receive a simplified explanation with links to detailed scientific papers.
Adaptive learning systems use hybrid RAG to generate personalized quizzes and study guides based on retrieved course materials.
5. Enterprise Knowledge Management
Large organizations employ hybrid RAG solutions to enable employees to query internal knowledge bases—spanning emails, reports, manuals—with synthesized answers that accelerate decision-making. For example, product managers can ask about past project timelines or customer feedback trends, receiving concise summaries integrating multiple data sources.
This breaks down information silos and fosters collaboration.
6. Financial Analysis and Advisory
Investment firms use hybrid RAG to analyze market reports, earnings calls transcripts, and news articles to generate timely investment insights. Automated systems can answer queries like “What is the impact of recent interest rate hikes on tech stocks?” by synthesizing heterogeneous data.
This enables faster, data-driven decision-making in volatile markets.
7. Scientific Research Assistance
Researchers utilize hybrid RAG tools to explore literature across disciplines, facilitating hypothesis generation and experiment design. For instance, a biologist studying gene editing can query multiple databases to obtain up-to-date findings and methodologies.
Such tools reduce literature review time and enhance interdisciplinary collaboration.
Industry | Use Case | Benefits |
|---|---|---|
Customer Support | Automated help desks | Reduced resolution time; consistent answers |
Healthcare | Clinical decision support | Improved accuracy; access to latest research |
Legal | Case law analysis | Efficient research; reduced manual workload |
Education | Intelligent tutoring systems | Personalized learning; contextual explanations |
Enterprise | Knowledge discovery | Faster insights; reduced information silos |
Finance | Market analysis & advisory | Timely insights; risk mitigation |
Scientific Research | Literature synthesis | Accelerated discovery; interdisciplinary support |
Challenges and Future Directions
Despite their promise, hybrid RAG models face ongoing challenges:
1. Retrieval Latency and Efficiency
Searching large corpora in real-time remains computationally expensive. Dense retrieval and cross-encoder re-ranking can introduce latency, limiting responsiveness in interactive applications.
Techniques such as approximate nearest neighbor search, caching popular queries, and distilling large models into smaller, faster variants are being explored to address this.
Moreover, balancing retrieval speed with accuracy requires careful engineering, especially when scaling to billions of documents.
2. Handling Ambiguity and Noisy Data
Poorly formulated queries or noisy knowledge bases can mislead retrieval modules, resulting in irrelevant or incorrect answers. For example, ambiguous questions without sufficient context may retrieve unrelated documents.
Data quality issues like outdated or conflicting information also pose risks to answer reliability.
Hybrid RAG systems need robust query understanding, query reformulation, and noise filtering mechanisms to mitigate these issues.
3. Evaluation Metrics
Current benchmarks struggle to fully capture the quality of hybrid-generated answers, especially regarding factuality, reasoning depth, and user satisfaction.
Metrics like Exact Match (EM) and F1 score focus on lexical overlap but may ignore answer coherence or correctness.
Human evaluation, fact verification tools, and new metrics that assess explanation quality and source attribution are active research areas.
4. Ethical Considerations
Ensuring transparency about answer sources and mitigating biases embedded in training data are paramount for trustworthy applications.
Hybrid RAG systems must provide citations or provenance for generated answers to build user trust.
Addressing harmful biases, misinformation propagation, and privacy concerns requires ongoing vigilance and governance frameworks.
Emerging Research Trends
End-to-end training of retrievers and generators to maximize synergy. Joint optimization can improve retrieval relevance and generation quality but involves complex training strategies and significant compute.
Multimodal retrieval incorporating images and video alongside text. For example, medical QA systems integrating radiology images with clinical notes to enhance diagnostic support.
Personalized retrieval, adapting results based on user profiles, preferences, and history to provide contextually relevant answers.
Explainable generation, providing citations or rationale alongside answers to enhance transparency and user trust.
Continual learning to update retrievers and generators incrementally as new data arrives without catastrophic forgetting.
Federated retrieval to enable privacy-preserving access to distributed knowledge bases across organizations.
For ongoing research insights, see Stanford’s CRFM Center for Research on Foundation Models.
Implementing Your Own Hybrid RAG Model: Best Practices
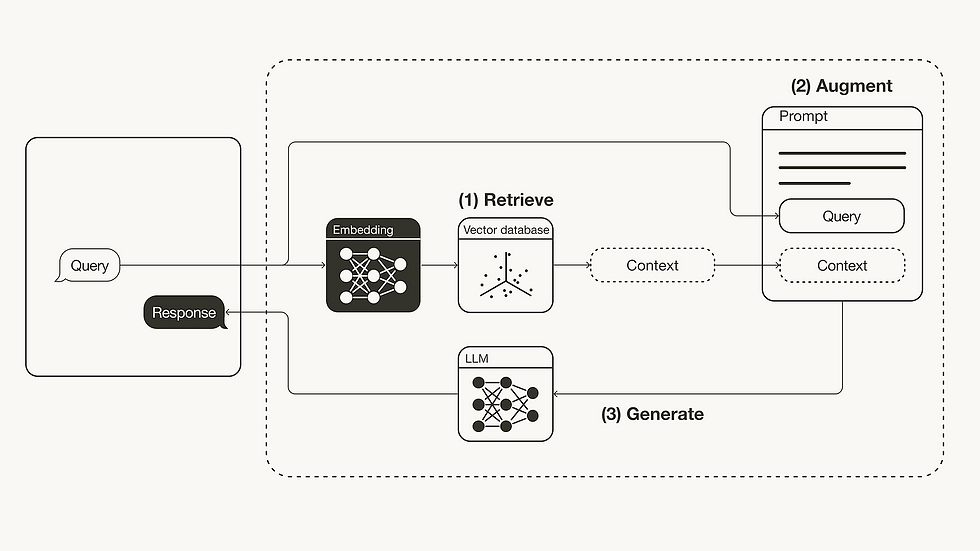
For practitioners eager to build hybrid RAG systems, consider the following guidelines:
Step 1: Define Your Domain and Knowledge Sources
Carefully select or curate your document corpus to ensure relevance and quality. For instance, a legal QA system should include statutes, case law, and regulatory guidelines, while excluding unrelated content.
Data preprocessing—cleaning, deduplication, and normalization—improves retrieval effectiveness.
Step 2: Choose Appropriate Retriever Architectures
Experiment with both dense (e.g., DPR) and sparse (e.g., BM25) retrievers; evaluate combined approaches for optimal coverage.
Leverage approximate nearest neighbor libraries like FAISS or Annoy to scale dense retrieval efficiently.
Consider fine-tuning retrievers on domain-specific query-document pairs to boost relevance.
Step 3: Select a Powerful Generator Model
Start with pre-trained seq2seq transformers such as T5 or BART fine-tuned on QA datasets relevant to your domain.
For highly specialized domains, consider further fine-tuning on in-domain data or instruction-tuning for improved task alignment.
Step 4: Integrate Re-ranking Modules
Implement cross-encoders or learned rankers to improve passage selection before generation.
Re-ranking can dramatically enhance answer quality by prioritizing the most relevant contexts.
Balance re-ranking accuracy with computational cost, possibly using cascaded retrieval pipelines.
Step 5: Fine-tune End-to-End Where Possible
Jointly training retriever and generator components can yield better overall performance but requires substantial computational resources and careful loss design.
Techniques like contrastive loss for retrievers combined with generation loss for decoders help align objectives.
Step 6: Evaluate Using Multiple Metrics
Combine traditional QA metrics (EM/F1) with human evaluation focused on factual correctness and fluency.
Leverage automatic fact verification tools and user feedback loops for continuous improvement.
Step 7: Monitor and Update Knowledge Bases Regularly
Keep your retrieval corpus current to maintain answer accuracy over time.
Implement incremental indexing pipelines to add, update, or remove documents efficiently.
Establish data governance policies to ensure quality and compliance.
FAQ: Common Questions on RAG-Based Question Answering
Q1: What does “hybrid” mean in hybrid RAG architectures?
Hybrid refers to combining multiple retrieval methods (dense + sparse) or integrating both retrieval and generative components into one cohesive system for improved QA performance. This hybridization leverages complementary strengths to enhance accuracy, coverage, and robustness.
Q2: Can hybrid RAG models handle real-time queries effectively? While latency can be a challenge due to retrieval overhead, optimizations such as approximate nearest neighbor search, caching, model distillation, and hardware acceleration help achieve near real-time responses in many applications. System design choices and infrastructure play critical roles in meeting latency requirements.
Q3: How does hybrid RAG compare with large language models like GPT-4? Hybrid RAG grounds its generated answers in external documents, reducing hallucination risk compared to standalone LLMs that rely solely on internal knowledge learned during pretraining. This makes hybrid RAG especially suitable for knowledge-intensive and domain-specific tasks where factual accuracy is paramount.
Q4: Are there open-source tools for building hybrid RAG systems? Yes—libraries like Hugging Face Transformers support retriever-generator pipelines; tools like Haystack provide end-to-end frameworks for hybrid RAG implementation, including dense retrieval, sparse retrieval, re-ranking, and generation. Open-source datasets and pretrained models further accelerate development.
Q5: What kinds of data sources are best suited for hybrid RAG? Structured corpora with well-maintained documents such as Wikipedia dumps, scientific articles, legal texts, or corporate knowledge bases yield the best results when paired with robust retrievers. Data freshness, domain specificity, and document quality significantly impact system effectiveness.
Conclusion: Harnessing the Power of Hybrid RAG Architectures
As AI continues advancing, hybrid Retrieval-Augmented Generation models stand at the forefront of delivering accurate, context-rich question answering solutions across industries. By blending efficient information retrieval with powerful generative transformers, these architectures address critical challenges of knowledge grounding and updateability—unlocking new possibilities for intelligent assistants, research tools, and enterprise applications alike.
To capitalize on this technology:
Invest in curated knowledge bases tailored to your domain.
Experiment with multi-modal and multi-retriever setups to cover diverse information types.
Prioritize factual accuracy via grounding, re-ranking, and explainability.
Stay abreast of evolving end-to-end training techniques that unify retriever-generator pipelines.
The future of question answering lies in these sophisticated hybrid systems that intelligently combine memory access with creative language generation—empowering humans with precise insights at unprecedented scale.


