Gemini 3 Deep Think Achieves 48.4% on Humanity's Last Exam and 3455 Codeforces Elo
- Aisha Washington

- Feb 13
- 5 min read

Google released Gemini 3 Deep Think on February 12, 2026, marking a tangible shift in how large language models handle complex reasoning. The update moves beyond standard chatbot capabilities, targeting verified problem-solving in physics, mathematics, and software engineering.
The most significant data point from this release is the model's performance on "Humanity's Last Exam." Gemini 3 Deep Think scored 48.4% without tool assistance. For context, OpenAI’s Deep Research tool (based on the o3 model) scored 26.6% roughly a year prior, while DeepSeek R1 sat at 9.4%. This performance gap suggests that the "Deep Think" architecture has successfully prioritized chain-of-thought reasoning over simple pattern matching.
This article analyzes the technical specifications, immediate user access methods, and the comparative performance data of Gemini 3 Deep Think against current market alternatives like GPT-5.2 Pro.
How to Enable Gemini 3 Deep Think in Google AI Ultra

For users with a Google AI Ultra subscription, accessing the new reasoning capabilities requires navigating a specific UI workflow. Google has not made "Deep Think" the default setting, likely due to the high inference cost and latency associated with deep reasoning models.
To activate the model:
Open the standard Gemini interface (gemini.google.com or the app).
Navigate to the model selection menu (often indicated by a + or model version dropdown).
Select the "Thinking" model option.
Look for a secondary toggle labeled "Deep Think" and switch it on.
Early user reports from Reddit indicate confusion regarding this interface. The "Thinking" mode is a category, while "Deep Think" is the specific high-compute feature. Users looking for the benchmarked performance must ensure the secondary toggle is active. Without it, the system defaults to a lighter reasoning model that does not match the 48.4% benchmark claims.
Developers and enterprise researchers access the model differently. Instead of a direct toggle, access is currently gated through an "Express Interest" form for the Gemini API, suggesting Google is managing compute allocation carefully for high-volume commercial use.
Benchmark Analysis: Humanity’s Last Exam and ARC-AGI-2
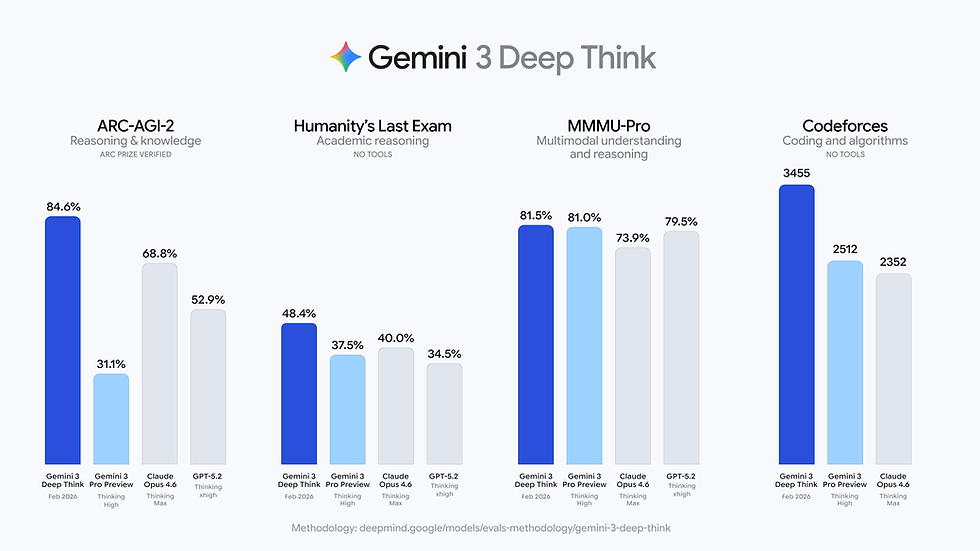
The technical credibility of Gemini 3 Deep Think rests on its scores in tests designed to be unsolvable by previous generation AI.
Humanity's Last Exam Performance
"Humanity's Last Exam" consists of high-level academic problems that typically require deep domain expertise to solve. The test was designed to prevent "benchmaxxing"—the practice of optimizing models specifically to ace standardized tests.
Gemini 3 Deep Think: 48.4%
OpenAI Deep Research (o3): 26.6%
DeepSeek R1: 9.4%
The 48.4% score is notable because it was achieved without external tools. The model relied solely on internal reasoning chains. Critics in the AI community argue that a score this high on such a niche dataset could imply some level of training data contamination (memorization), but the breadth of performance across other metrics suggests genuine generalization.
Scientific and Coding Metrics
Google validated the model through third-party organizations to counter claims of internal bias.
ARC-AGI-2: The model scored 84.6%, verified by the ARC Prize Foundation. This test measures the ability to learn new logical rules on the fly, rather than recalling memorized knowledge.
Codeforces: It holds an Elo rating of 3455, placing it in the top tier of competitive programming.
International Olympiads: The model achieved gold medal standards in the 2025 International Math, Physics, and Chemistry Olympiads.
Real-World Applications for Gemini 3 Deep Think

High benchmark scores often fail to translate into usability. However, early case studies provided by Google and verified by university partners show specific utility in academic workflows.
Correcting Physics Research at Rutgers
In a collaboration with Rutgers University, Gemini 3 Deep Think analyzed a pre-print paper on high-energy physics. The paper had passed initial human reviews. The model identified a logical inconsistency in a mathematical proof that human reviewers missed. This moves the use case from "generating text" to "auditing logic," a function previously reserved for senior PhD candidates.
Materials Science Engineering at Duke
Duke University researchers used the model to solve a fabrication issue. The challenge involved growing a specific film aimed at >100 μm thickness, where previous recipes failed to maintain structural integrity. The model proposed a new chemical synthesis recipe that achieved the desired thickness.
These examples differentiate Gemini 3 Deep Think from GPT-5.2 Pro. While GPT-5.2 remains a strong generalist, Gemini’s tuning focuses on widely branching possibilities where a single error invalidates the entire result.
User Experience and Market Comparison
The reception of Gemini 3 Deep Think among the tech-savvy public has been mixed, revealing a divide between casual users and technical specialists.
Comparison to OpenAI and DeepSeek
Users familiar with OpenAI’s ecosystem note that the jump from Gemini’s previous Pro version to Deep Think feels more substantial than the recent upgrade to GPT-5.2.
GPT-5.2 Pro: Users describe it as a marginal improvement over GPT-4, focused on speed and conversational fluidity.
Gemini 3 Deep Think: Viewed as a specialized tool. It is slower and more deliberate.
A Reddit user noted that for general queries, they still prefer Claude or ChatGPT due to speed. However, for "research and mathematical proofs," Gemini has become the preferred engine. This bifurcation suggests the market is moving away from "one model to rule them all" toward specialized engines for specific cognitive tasks.
Weaknesses in Coding and Agents
Despite the high Codeforces Elo, practical coding experience varies. Users report that while the model can solve algorithmic puzzles (LeetCode style), it struggles with large-scale software engineering tasks compared to Claude 3.7 or the latest GPT iterations. The "Agent" capabilities—where the model autonomously executes multi-step tasks—are also reported as less reliable than Anthropic’s offerings.
The "Lobotomy" Concern
A recurring theme in user feedback is the fear of safety alignment degrading performance. Comments describe a "mental health" concern for models, where aggressive Reinforcement Learning from Human Feedback (RLHF) forces the model to refuse complex queries or provide overly sanitized answers. While Gemini 3 Deep Think is currently unrestricted in its reasoning mode, users are wary that future updates might throttle its creative problem-solving abilities to align with safety protocols.
Gemini 3 Deep Think Pricing and Accessibility

Google has bundled this model into the existing Google AI Ultra subscription. This aggressive pricing strategy attempts to undercut enterprise competitors who charge usage-based fees for high-reasoning models.
For developers, the API availability remains limited. The "Express Interest" gate implies that Google is still scaling the hardware infrastructure required to support the massive inference compute these models demand. Until general API availability opens, Gemini 3 Deep Think remains primarily a tool for individual power users and select academic partners.
The release of Gemini 3 Deep Think establishes a new baseline for reasoning-heavy AI. By focusing on non-tool-assisted performance in verified exams like "Humanity's Last Exam," Google has shifted the goalposts from chat capability to autonomous research verification. The industry focus now turns to how quickly OpenAI will respond with a widely available version of its o3-heavy models.
Frequently Asked Questions
Q: How do I turn on Gemini 3 Deep Think mode?
A: In the Gemini web or mobile interface, select the "Thinking" model from the dropdown menu. Once selected, toggle the specific "Deep Think" switch that appears. This feature is currently limited to Google AI Ultra subscribers.
Q: Is Gemini 3 Deep Think better than OpenAI o3?
A: In the "Humanity's Last Exam" benchmark, Gemini 3 Deep Think scored 48.4% compared to the o3-based Deep Research tool's 26.6%. This indicates superior performance in handling complex, novel academic problems without external tools.
Q: Can Gemini 3 Deep Think write code?
A: Yes, the model has a Codeforces Elo rating of 3455, making it highly capable at algorithmic problems. However, some users report it is less effective than Claude or GPT-5.2 at managing large, multi-file software engineering projects.
Q: What is the difference between Gemini Pro and Deep Think?
A: Gemini Pro is optimized for speed and general tasks, while Deep Think is a reasoning model designed to pause and "think" before answering. Deep Think is significantly slower but better suited for math, science, and logic puzzles.
Q: Is Gemini 3 Deep Think free to use?
A: No, access to the Deep Think model requires a paid Google AI Ultra subscription. Developers and researchers wanting API access must currently apply via an interest form.


