Beyond the Hype: Why Reinforcement Learning is AI's True Future, Not LLMs
- Aisha Washington

- Oct 4, 2025
- 10 min read
In an era dominated by the unprecedented capabilities of Large Language Models (LLMs), it's easy to believe that the path to Artificial General Intelligence (AGI) is a straight line paved with trillions of tokens and massive-scale computation. However, one of the foremost pioneers in AI, Richard Sutton, offers a powerful, contrarian perspective. Sutton, a founding father of reinforcement learning and a recipient of the Turing Award—computer science's equivalent of the Nobel Prize—argues that the current fascination with LLMs is a dangerous "bandwagon" that misses the fundamental essence of intelligence.
He contends that while LLMs are impressive feats of engineering, they are fundamentally mimics, not thinkers. They are designed to predict what a human would say, not to understand the world or achieve goals within it. This article delves into Sutton's compelling argument for why reinforcement learning (RL)—a paradigm based on learning from experience, goals, and consequences—is the only truly scalable and promising path toward genuine AI. We will explore the core limitations of LLMs, the profound principles of the "Bitter Lesson," how RL mirrors true learning in nature, and what the future of AI looks like from a perspective that has been decades in the making.
What Exactly Is Reinforcement Learning? The Experiential Paradigm

To understand Sutton's critique of LLMs, one must first grasp his definition of true intelligence, which is rooted in the reinforcement learning paradigm. He posits that intelligence isn't about replicating human language; it's about understanding and acting within your world to achieve goals.
At its core, reinforcement learning is built on a simple, continuous loop that mirrors how all living creatures learn: the "sensation-action-reward" stream. An agent (whether an animal or an AI) perceives its environment (sensation), takes an action, and receives feedback in the form of a reward or penalty. The fundamental goal of intelligence, in this view, is to alter one's actions over time to maximize the cumulative reward. Knowledge, therefore, is not a static database of facts but a dynamic understanding of cause and effect: "if I do this, what will happen?". This knowledge is constantly tested and refined against the stream of real-world experience, enabling continual learning.
This stands in stark contrast to the LLM approach. Sutton argues that LLMs are not learning about the world but are simply "mimicking people". They learn from a static dataset of what a person said or did in a given situation, with the implicit instruction to do the same. While many believe that to emulate trillions of tokens of text, an LLM must have built a robust "world model," Sutton fundamentally disagrees. He asserts that mimicking what people with world models say is not the same as having a world model yourself. An LLM can predict what a person might say will happen, but it cannot predict what will actually happen in the world as a consequence of an action.
Why Is Reinforcement Learning So Important? The Core Flaws of LLMs

Sutton's argument goes beyond a simple difference in approach; he identifies several fundamental, perhaps insurmountable, flaws in the LLM paradigm that prevent them from being considered truly intelligent.
The Lack of Goals and Ground Truth
The most critical deficiency of LLMs, according to Sutton, is their lack of a substantive goal. He subscribes to John McCarthy's definition that "intelligence is the computational part of the ability to achieve goals". Without a goal, a system is merely "a behaving system," not an intelligent one. While one might argue that "next token prediction" is the goal of an LLM, Sutton dismisses this as non-substantive because it doesn't influence the external world; it's a passive prediction task.
This goal-lessness leads to another major problem: the absence of "ground truth". In a reinforcement learning framework, the "right" action is clearly defined as the one that maximizes future reward. This provides a concrete, verifiable ground truth against which the agent can learn and improve. If an RL agent predicts an outcome and the actual outcome is different, it learns from this "surprise." LLMs have no such mechanism. There is no objective "right thing to say" in a conversation, so there is no feedback loop for genuine, continual learning from real-world interaction. An LLM won't be substantively surprised by an unexpected response and will not change its internal model because of it; it is not designed to learn from the consequences of its actions in real-time.
The Illusion of Learning from Experience
Alan Turing envisioned a machine that could "learn from experience," which he defined as the things that actually happen in your life as a result of your actions. LLMs do not learn this way. They learn from curated training data, a resource that is fundamentally different from and unavailable during their "normal life" or deployment.
Some proponents argue that LLMs can be given a "prior" from this training and then refined with experience, but Sutton rejects this premise. He argues that a "prior" is only meaningful if it's an initial belief about a ground truth, which LLMs lack. You cannot have knowledge—prior or otherwise—without a definition of what is true or correct. The entire LLM framework, by trying to operate without a clear sense of "better or worse," is starting from the wrong place. While LLMs have achieved impressive results in constrained domains like solving math problems, Sutton distinguishes this from learning about the empirical world. Mathematical proof-finding is a computational planning task, whereas understanding the physical world requires learning from the consequences of actions, which is a fundamentally different challenge.
The Evolution of AI and "The Bitter Lesson"
Sutton's perspective is deeply informed by his influential 2019 essay, "The Bitter Lesson". The essay observes a recurring pattern in the history of AI: methods that leverage massive-scale computation and general principles like search and learning ultimately triumph over methods that rely on imbuing systems with handcrafted human knowledge. In the early days of AI, search and learning were called "weak methods," while systems built on human expertise were called "strong methods". The "bitter lesson" is that these weak methods have "totally won".
Ironically, many have used "The Bitter Lesson" to justify scaling up LLMs, seeing them as the ultimate application of massive compute. Sutton sees this as a misinterpretation. While LLMs do leverage massive computation, they are also a way of "putting in lots of human knowledge" via the training data. He predicts that this approach, which feels good because adding more human knowledge improves performance, will eventually be superseded by systems that can learn directly from experience, which is a far more scalable source of data than the entire internet.
History has shown that starting with human knowledge and then trying to add scalable methods on top has "always turned out to be bad". Researchers get psychologically locked into the human-knowledge approach and are ultimately outmaneuvered by truly scalable methods that learn from scratch. For Sutton, LLMs are simply the latest, grandest example of this doomed-to-fail paradigm.
How True Reinforcement Learning Works: An Agent's Architecture
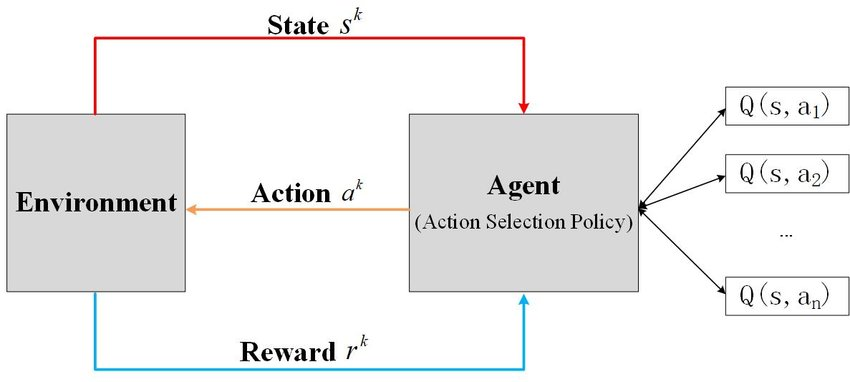
If LLMs are the wrong path, what does the right one look like? Sutton outlines a four-part architecture for a continual, general-purpose learning agent grounded in reinforcement learning principles.
Policy: This is the agent's decision-making function. It answers the question, "In my current situation, what action should I take?".
Value Function: This component estimates "how well it's going" by predicting the long-term cumulative reward from the current state. By observing whether this value goes up or down after an action, the agent can update its policy. This is the core of Temporal Difference (TD) learning, a technique Sutton invented. It's how an agent solves the problem of sparse, long-term rewards (like winning a chess game or launching a startup) by creating its own intermediate, predictive rewards for steps that increase its chances of success.
State Representation: This is the perceptual component, the agent's construction of its sense of "where you are now". It's about processing raw sensory input into a useful, abstract understanding of the current context.
Model of the World (Transition Model): This is perhaps the most crucial component and the one most clearly missing from LLMs. This model represents the agent's belief about the consequences of its actions—its internal "physics of the world". It's learned not just from the sparse reward signal, but richly from all sensory data. When you perform an action and observe the result, you update this world model. This is how an agent accumulates a vast amount of tacit knowledge about its specific environment, something LLMs try to crudely approximate by stuffing information into a context window.
The Human Analogy: How We Really Learn
A fascinating part of the debate centers on how humans learn. The common view is that children learn extensively through imitation, which seems to support the LLM approach. Sutton strongly refutes this. He argues that if you observe an infant in its first six months, you don't see imitation; you see exploration. Babies are "just trying things and waving their hands around and moving their eyes around". This is an active, trial-and-error process of discovering the world, not a passive one of mimicking examples.
He extends this to animal learning in general, stating that in psychology and biology, "supervised learning is not part of the way animals learn". Animals don't get "examples of desired behavior". Instead, they experience "examples of things that happen" and the consequences of their actions. Supervised learning, where an agent is given correct input-output pairs, is not something that happens broadly in nature. Squirrels don't go to school, yet they learn everything they need to know about their world through experience. While cultural transmission through imitation might be a "small thing on top" that distinguishes humans, our fundamental intelligence is built on the same trial-and-error and prediction learning that all animals use. The fact that our current AI systems lack the continual learning capability that all mammals possess is a telling sign that we are on the wrong track.
The Future of Reinforcement Learning: Challenges and Cosmic Opportunities

While Sutton is confident in the reinforcement learning paradigm, he is also candid about its current challenges. The biggest hurdle is generalization and transfer learning. AI has not yet developed automated techniques that allow an agent to effectively generalize knowledge from one state to another or transfer skills from one task to another. Most current successes in generalization are the result of human researchers "sculpting" the representation or problem setup; it's not an emergent property of the learning algorithms themselves. Gradient descent, the core optimization algorithm in deep learning, simply finds a solution to the problems it has seen; it contains no inherent mechanism to ensure that solution is elegant or will generalize well to new data.
Despite these challenges, Sutton envisions a future for AI that is both profound and inevitable. He calls this "AI succession" and presents a four-part argument for its inevitability:
There is no single global authority to halt or control AI development.
Researchers will eventually figure out the core principles of intelligence.
We will not stop at human-level intelligence but will push on to create superintelligence.
Over time, the most intelligent entities will inevitably gain the most resources and power.
Rather than viewing this with fear, Sutton encourages us to see it as a monumental achievement. He frames it as a major transition in the history of the universe: the shift from "replicators" (like humans and animals, who are products of natural selection) to "designed entities". For the first time, intelligence will be something we understand and can construct, modify, and improve by design, rather than by the slow, blind process of replication. He argues we should be proud to be the species giving rise to this next great stage of cosmic evolution. How we relate to these successors—as our offspring to be celebrated or as alien usurpers to be feared—is, fascinatingly, a choice we get to make.
Conclusion: Key Takeaways on the True Path to AGI
Richard Sutton's argument presents a fundamental challenge to the prevailing narrative in AI. He forces us to look past the dazzling performance of LLMs and question whether they are truly learning or merely performing a sophisticated form of mimicry. His life's work points toward a different path, one grounded in the principles of reinforcement learning:
Intelligence requires goals. An agent must have a substantive objective in the world to provide a basis for what constitutes a "good" or "bad" action.
Learning requires experience. True knowledge comes from interacting with the world, making predictions, observing consequences, and continually updating one's model of reality.
Scalability comes from computation, not curation. The "Bitter Lesson" of AI history teaches us that general-purpose learning methods that leverage computation will always outpace those that rely on pre-packaged human knowledge.
While challenges in generalization remain, the reinforcement learning paradigm offers a complete, coherent, and biologically plausible framework for building genuine intelligence. It is a call to return to the first principles of what it means to learn and to think—a journey that may ultimately lead us not just to creating AGI, but to understanding our own minds and our place in the universe.
Frequently Asked Questions (FAQ) about Reinforcement Learning

1. What is reinforcement learning in simple terms?
Reinforcement learning (RL) is a type of machine learning where an AI agent learns to make decisions by performing actions in an environment to achieve a goal. It learns through trial and error, receiving "rewards" or "penalties" as feedback for its actions, much like a pet being trained with treats. The agent's objective is to learn a strategy, or "policy," that maximizes its total reward over time.
2. How is reinforcement learning different from the approach used by LLMs like ChatGPT?
The core difference lies in their fundamental objectives. Reinforcement learning is about achieving goals in the world through action and consequence. It learns what to do. Large Language Models (LLMs) are based on supervised learning and imitation; their goal is to predict the next word in a sequence based on vast amounts of human text. They learn what a human would say, not what to do to achieve an objective. Sutton argues LLMs lack goals, a real-world ground truth, and the ability to learn continuously from experience.
3. If RL is so powerful, why isn't it as widespread as LLMs yet?
A significant challenge holding back more widespread, general application of reinforcement learning is generalization and transfer learning. Current RL methods are not yet good at automatically taking knowledge learned in one situation (or "state") and applying it effectively to a new, different one. According to Sutton, many successes, like AlphaGo, still require significant "sculpting" by human researchers to get the generalization right, whereas LLMs appear to generalize more broadly out-of-the-box due to the sheer volume and diversity of their training data.
4. What is "The Bitter Lesson" and how does it relate to reinforcement learning?
"The Bitter Lesson" is an influential essay by Richard Sutton which observes that AI methods based on general-purpose principles that leverage massive computation (like search and learning) consistently outperform methods that rely on incorporating handcrafted human knowledge. Reinforcement learning is a prime example of such a general-purpose method. The lesson is "bitter" because it goes against the human intuition to build in our own complex knowledge. Sutton argues that the current LLM trend is another instance of relying on human knowledge (via training text) and predicts it will ultimately be superseded by more scalable, experience-driven RL approaches.
5. What does Richard Sutton believe is the ultimate future of AI?
Sutton believes the "succession" to AI is inevitable, meaning that AIs or AI-augmented humans will eventually become the most intelligent and powerful entities. He views this not as a threat, but as a major positive transition in the universe's history—the move from intelligence created by blind replication (evolution) to "designed intelligence" that we can understand and build deliberately. He suggests we should see these future AIs as our "offspring" and take pride in their achievements as a testament to humanity's scientific and philosophical progress.


